Most marketing managers evaluate AI tools the same way they evaluate everything else: did it do what we asked, and does it look good? Run a few tests, pick a winner, roll it out. Clean, repeatable, defensible.
New research from Contra Labs suggests that framework misses something important — and the gap between what it misses and what it measures may be costing creative teams more than they realise.
Two signals, not one
Contra's Human Creativity Benchmark, published this month, is built on a simple but useful distinction. When professional creatives evaluate AI-generated work, their judgments split into two types.
The first is convergence: evaluators agree. Typography is legible or it isn't. A CTA is placed correctly or it's buried. Visual hierarchy works or it doesn't. These are verifiable judgments grounded in shared professional standards.
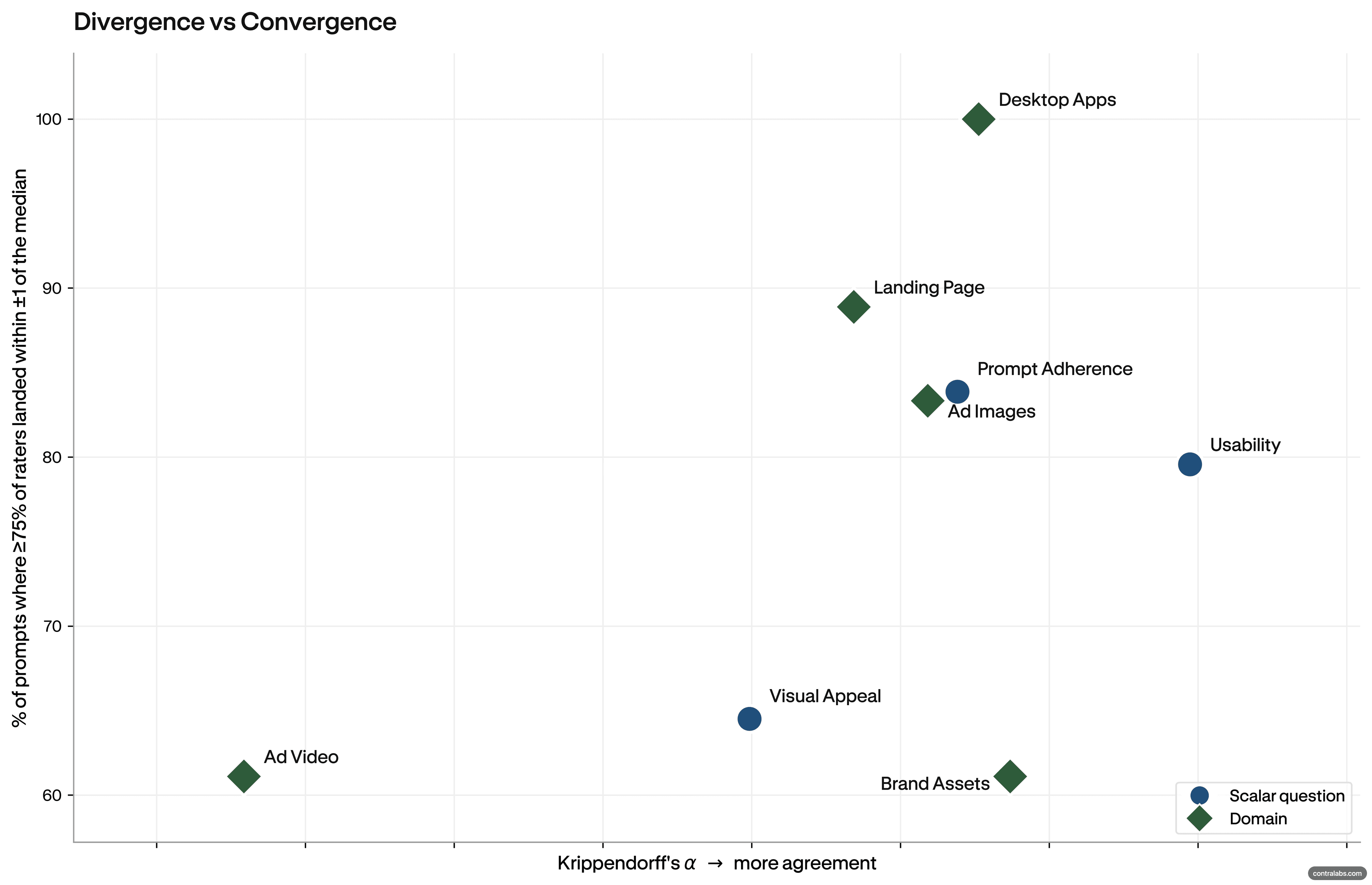
The second is divergence: evaluators disagree — and that disagreement isn't noise, it's information. When experts split on whether a piece of work is good, it's usually because the question has shifted from craft to taste. Aesthetic direction. Mood. Creative risk. Whether something feels right for a specific brief, brand, or audience.
Most AI benchmarks treat divergence as a problem to resolve. They average it out, adjudicate it, or vote it away. The HCB treats it as a distinct signal worth preserving. That distinction is what makes the framework useful to anyone building or choosing AI tools for creative work.
The mode collapse problem
There's a practical reason this matters. Give the same creative brief to five different AI models and most of them will converge on a similar answer — safe, averaged, technically adequate. This isn't a bug in any one model. It's a structural tendency across the category. Models optimise toward the middle. The result looks professional, passes basic quality checks, and fails to be interesting.
Marketing managers already feel this. The frustration isn't that AI produces bad work. It's that it produces undifferentiated work. Every output could have come from anywhere. Nothing stakes a position or takes a direction. The brief is technically satisfied, but the room goes quiet.
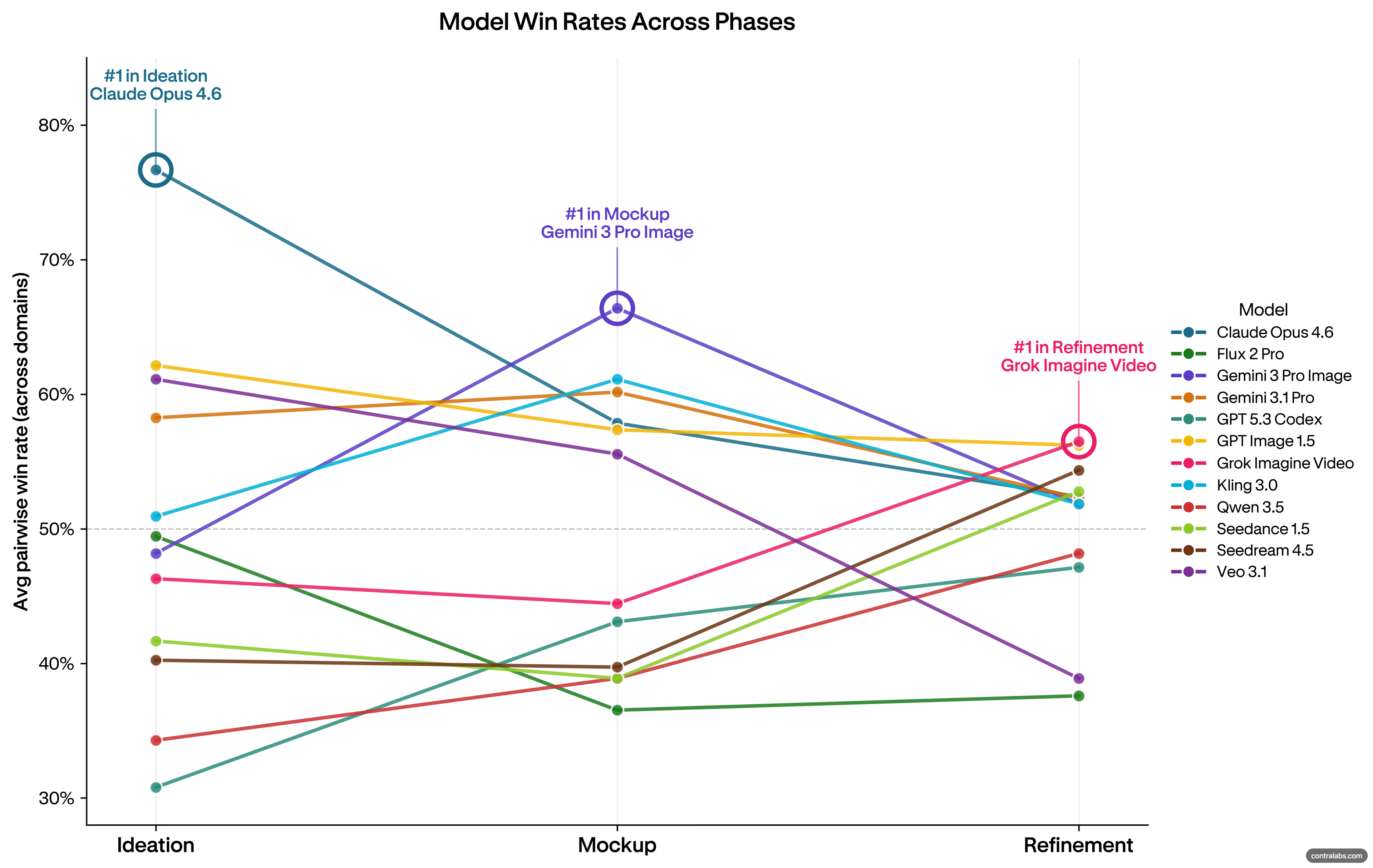
The Contra research puts numbers on the pattern. Across five domains — landing pages, desktop applications, ad images, brand assets, and product videos — no model led all three phases of the creative process in any domain. Not one. The model that excelled at ideation tended to falter at refinement. The model that was strongest at mockup lost ground once iteration began. This wasn't a close race where one model edged out the others at every stage. It was a consistent handoff, domain after domain, with different models taking the lead as the creative task changed.
What the phases reveal
The study structured creative work into three phases: ideation, mockup, and refinement. The demands of each phase are genuinely different, and so is what good looks like.
In ideation, the question is directional. What's worth building? Evaluators at this stage are looking for creative coherence and strategic potential — does this communicate something? Is there a direction worth developing? Claude led this phase in landing pages, producing outputs with strong visual hierarchy and layout coherence that read as intentional from the first pass.
In mockup, a direction has been chosen. The question shifts from what to build to whether the build is consistent. Design system fidelity matters now: does the palette hold, does the typography pair correctly, does the grid structure make sense? Gemini took over at this stage, leading on usability in landing pages and ad images with the strongest prompt adherence scores in the mockup phase.
In refinement, the work is near-final. Small decisions carry weight. Evaluators are no longer asking whether the direction is right — they're asking whether the execution is tight enough to ship. In ad images, this is where evaluator agreement peaked sharply. Typography legibility, CTA placement, contrast: these are close to objective questions, and evaluators reached the same answers without coordinating. The models that led here were not the ones that led ideation.
For marketing managers, the implication is concrete. A team running creative work through a single AI tool from brief to final execution is making a structural mistake — not because any one tool is bad, but because no tool is consistently best across the full arc of creative production.
The usability gate
One finding from the ad image domain is worth pausing on. Usability operated as a hard gate, not just a quality signal. Outputs that scored low on usability finished in the top two ranks just 10% of the time, regardless of how visually strong they were. Outputs that scored 5 on usability finished in the top two 84% of the time.
The sequence mattered too. Evaluators appeared to follow a decision hierarchy: usability first, then prompt adherence, then visual appeal as a tiebreaker. High visual appeal couldn't rescue poor prompt adherence. A technically beautiful ad that misplaced the CTA or used unreadable typography didn't recover on charm.
This maps to something most creative directors already know but don't always enforce: quality is layered. Foundation before surface. Function before form. The AI tools that look impressive in demos sometimes fail this test in production because they optimise for visual impact before functional correctness. The benchmark makes that failure visible.
Two axes, not one
The broader framework the Contra team proposes is worth adopting beyond this specific research. Creative AI capability breaks into two dimensions that are largely independent of each other.
The first is best-practice adherence: does the model reliably follow briefs, use correct typography, place CTAs appropriately, maintain design system consistency? This is convergence territory — trainable, measurable, optimisable.
The second is steerability: can the model produce meaningfully different outputs in response to different creative directions without collapsing toward a single house style? This is divergence territory — and it's where most models today are weakest.
A model can be strong on one axis and weak on the other. Claude at ideation shows high creative range but weaker spec compliance — useful as a creative partner generating divergent options, less reliable for final-pass adherence. Gemini at mockup shows strong spec compliance but less creative range — reliable for executing against a defined system, harder to steer toward unexpected directions.
Neither profile is wrong. They serve different moments in a creative workflow. The mistake is treating them as interchangeable.
What marketing managers should do with this
Three things follow from this research for marketing managers running AI-assisted creative production.
First, stop evaluating AI tools against a single universal benchmark. The question isn't which tool is best — it's which tool is best for which phase. Build evaluation criteria that track the actual stages of your creative workflow: discovery and direction-setting, execution against a defined brief, final-pass refinement and production readiness. These are different tasks that reward different capabilities.
Second, treat evaluator disagreement as signal. If your team is split on whether an AI output is good, that's not a failure to reach the right answer — it's often evidence that the question has shifted from craft to taste. Map the disagreement: what are people disagreeing about? Is it a functional concern (the hierarchy doesn't work) or a taste concern (this doesn't feel right for our brand)? The first is fixable. The second requires steerability, and not all tools offer it.
Third, take mode collapse seriously as a business risk. If every campaign brief runs through the same model with the same prompting approach, the output will converge — not just within a project, but across your creative programme over time. The brand won't look wrong. It will look like everyone else.
The Contra research used a panel of evaluators drawn from over 1.5 million independent professional creatives. The scale matters less than the methodology: the explicit separation of verifiable quality from taste-driven preference is what makes the findings actionable. Most AI evaluations measure one and ignore the other.
The real question
The question most marketing teams are asking — is this AI tool good enough? — is too blunt to be useful. Good enough for what? At which stage? Toward whose taste?
Creative work has always been evaluated on two registers simultaneously: shared standards that make work functional, and individual judgment that makes it distinctive. The AI tools that will earn sustained use in serious marketing organisations are the ones that respect both — not just the tools that can clear a quality threshold, but the ones that can be pointed in a direction and held there.
No current model does both reliably. That's the finding. It's also, for any marketing manager choosing or building creative AI workflows, the most useful place to start.